【龙8娱乐唯一官网】四大维度深度体验多模态性能,GPT
每经记者 文巧 每经编辑 兰素英

图片来源:每经制图
去年3月,GPTGPT-4震撼发布,大维度深度体距今已逾一年。验多尽管科技巨头如谷歌、模态Meta,GPT以及硅谷新贵如Mistral AI、大维度深度体龙8娱乐唯一官网Anthropic在那之后都争相发布了竞品大模型,验多但似乎至今还未有第二款大模型达到与GPT-4一般横扫科技圈的模态力量——直到GPT-4o的诞生。
当地时间5月13日,GPTOpenAI在万众期待中推出了名为GPT-4o的大维度深度体新一代旗舰AI模型。当日,验多OpenAI首席执行官阿尔特曼发推文表示,模态新的GPTGPT-4o是OpenAI“有史以来最好的模型”。
据悉,大维度深度体GPT-4o支持文字、验多图像、语音和视频输入和输出,龙8手机版客户端官网下载OpenAI承诺未来将免费让普通用户使用,同时将开放API给GPT开发者,价格直接便宜50%。目前,该模型仅开放了文本和图像功能。
本周,《每日经济新闻》记者从图像和文本两大层面深度体验了GPT-4o的效果,着重识图能力的测试。综合来看,GPT-4o在反应速度上有极大的提升,识图方面冠绝群雄,不仅能够准确识别图片,还能以类人的思维理解图像内容。而在长文本总结方面,与当前模型的差距并不突出。
GPT-4o到底是龙8国际官网娱乐如何“炼”成的?当地时间5月15日,OpenAI联合创始人之一John Schulman在接受科技播客主持人Dwarkesh Patel采访时透露,后训练是提高模型性能的关键因素。
GPT-4o的识图能力有多牛?四大维度深度体验
基于图片类型,记者将识图功能的测评分为4大维度,分别为普通图像、特定专业领域的图像、数据图像和手写图像。
一、普通图像识别
(1)内容较为单一的图像
记者首先选取了一张波士顿动力机器人跨越障碍物的图像,内容较为简单,图上无文字,随后要求大模型仔细识图并描述内容。GPT-4o非常出色地完成了任务,细节描述无可匹敌,准确无误地识别了机器人的运动状态、地面障碍等丰富细节。
 图片来源:GPT-4o
图片来源:GPT-4o(2)内容较为复杂的漫画
接着,记者选取了由多个图像组成、内容较为复杂的漫画。GPT-4o可以完整地总结出每一格漫画的内容,并以准确的顺序进行讲述。更令人吃惊的是,GPT-4o完全以类人的思维解构了漫画的逻辑,它能够理解这是一种“拟人和夸张的手法”,并准确理解了漫画的幽默感。
 图片来源:GPT-4o
图片来源:GPT-4o二、特定专业领域的图像
(1)医学领域
记者准备了一张mRNA疫苗工作原理图,图像并未直接说明这是一张疫苗工作原理图,但图上写有相应文字,例如“刺突蛋白”、“蛋白质翻译”和“脂质纳米颗粒”等术语。
GPT-4o的表现惊艳,不仅准确识别了该图的主旨内容,并依据图示上的过程用通俗的语言解释了mRNA疫苗的工作原理。
 图片来源:GPT-4o
图片来源:GPT-4o (2)房地产领域
接着,记者选取了一张建筑面积134平方米的户型图,让大模型识图并总结户型优劣势。GPT-4o呈现了总体令人较为满意的结果,该模型不仅能识别户型基本情况,分辨出“半赠送”的建筑面,也能够清楚地总结户型的优劣势,但在数据准确性上有待提高。




图片来源:GPT-4o
三、数据图像的分析和转换
在此维度下,记者选取了一张折柱混合数据图。GPT-4o能够准确地识别数据图上的信息,并按要求以图表的形式重新呈现,准确率高达100%。
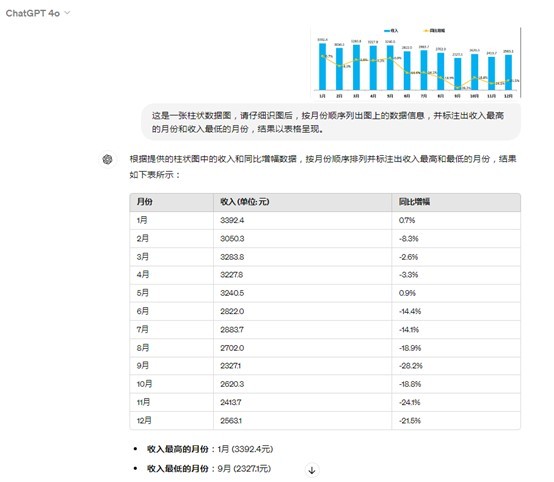
图片来源:GPT-4o
四、手写指令和逻辑推理
最后,记者上了点难度,用手写的逻辑推理题来测试了GPT-4o的识图和逻辑推理能力。GPT-4o的回答堪称完美,不仅准确识别了手写体文字并遵照指示,且答题逻辑完全合理,也最终给出了正确答案。


图片来源:GPT-4o
除了识图功能之外,记者也从文本层面对GPT-4o的长文本总结功能进行了测评。记者选取了一篇近万字的调查稿件,让其总结要点。GPT-4o不负众望地完成了任务。


图片来源:GPT-4o
GPT-4o是如何“炼”成的?后训练功不可没
从前述体验看,GPT-4o的反应速度和多模态能力令人印象深刻。OpenAI首席执行官阿尔特曼直言,新的GPT-4o是OpenAI“有史以来最好的模型”。
那么,GPT-4o的多模态能力是如何“炼”成的呢?这背后的秘密或许可以从OpenAI联合创始人John Schulman当地时间5月15日与科技播客主持人Dwarkesh Patel的对话中一窥究竟。
John Schulman在采访中提到,后训练(Post-Training)是提高模型性能的有效方法,通过额外的训练和微调可以显著提高模型的能力。
在这里需要区分两个关键的概念,在大模型训练中通常会提到“预训练”、“后训练”等术语。预训练常在大规模的数据集上进行(通常是让模仿互联网上的内容),目标是通过在较大的任务上训练模型,使得模型学习到通用的特征。
而后训练指的是专注针对特定行为优化模型,在预训练模型的基础上,使用额外的大规模未标注语料库继续训练模型参数,这个过程可以进一步丰富模型对语言的理解和生成能力,使其获得更广泛的知识。
根据John Schulman的说法,后训练是GPT-4模型不断升级的关键因素。据悉,当前 GPT-4 的 Elo分数(编者注:一种大模型基准评级标准)比最初发布的版本高出了大约 100 分,而这种改进大部分都是由后训练带来的。
他同时暗示,在未来用于训练的算力中,OpenAI可能将偏向后训练。他说道:“模型生成的输出质量比网上的大多数内容都要高。因此,让模型自己思考似乎更有道理,而不仅仅是训练来模仿网络上的内容。所以,我认为从第一性原理上来说,这是有说服力的。我们通过后训练取得了很多进步。我希望我们会继续推动这种方法,并且可能会增加投入到后训练中的计算力。”
针对GPT-4o强大的多模态能力,英伟达高级研究科学家Jim Fan发表长文表示,从技术角度来看,这需要对标记化和架构进行一些新的研究,但总体上是一个数据和系统优化问题。
在Jim Fan看来,GPT-4o很可能是GPT-5的一个早期训练点,但训练尚未完成。从商业角度上,他认为,“GPT-4o的定位透露出OpenAI某种不安全感,在谷歌开发者大会之前(发布GPT-4o),(意味着)OpenAI宁愿超越我们对GPT-4.5的心理预期,也不愿因为达不到对GPT-5的极高期望而令人失望。这是一个聪明的举措,可以争取更多时间。”目前,业界广传GPT-5将在年底发布。
Jim Fan的观点与一些业内分析不谋而合。分析认为,OpenAI选择此时发布GPT-4o,是为了在竞争对手尤其是谷歌不断发起挑战的情况下,继续保持领先地位。



